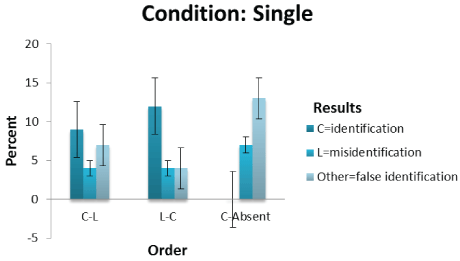
Figure 1: Shows the culprit, lookalike and other scores plotted against C-L, L-C and C-absent sequence order for single sequential line-up presentations.

Sandie Taylor* Lance Workman Rebecca Hall
School of Psychology and Therapeutic Studies, University of South Wales, United Kingdom*Corresponding author: Sandra Taylor, School of Psychology and Therapeutic Studies, University of South Wales, UK, E-mail: sandra.taylor@southwales.ac.uk
Previous research shows that sequential line-up presentations reduce the extent of ‘relative-judgment’ decision making in culprit-present lineups. At the same time, however, such presentations increase the chances of misidentifying an innocent person who resembles the culprit in culpritabsent line-ups. The order of appearance of culprit and ‘lookalike’ faces in a sequential line-up presentation has been found to influence the identification and misidentification rate. In the present study footage of a shoplifter was shown followed by a face recognition task using sequential line-up presentations. A design was adopted which manipulated three variables: single versus massed and distributed repetition lineup conditions; culprit-present versus culprit-absent (with a ‘lookalike’ resembling the facial features of the culprit); and early versus late order presentations. The culprit appeared either before or after the lookalike (including its repetition) in the sequence. In three conditions where the lookalike appeared before the culprit, it was hypothesized that interference of overlapping facial features would create a ‘misinformation effect’. In three conditions the culprit appeared before the lookalike and acted both as a control comparison and to test for Signal Detection Theory (SDT). The three culprit-absent conditions helped to establish the effectiveness of the lookalike face manipulation. Backward Hierarchical Log-Linear analysis established that the rate of identification is higher when the lookalike face appears before the culprit’s in all line-up sequences. Misidentification rate was higher when the lookalike appeared late in the line-up sequence and therefore after the culprit’s face (supporting SDT). Misidentification rate was similar in culprit-absent and culprit-present line-up presentations. Misidentifications increased over false identifications in massed repetition culprit-absent line-ups only (suggesting good lookalike manipulation). For single and distributed culprit-absent line-ups, there was no difference between misidentifications and false identifications. Moreover, the presentation of the lookalike face before that of the culprit’s failed to induce a misinformation effect. A spacing effect in the predicted direction (identification highest in distributed repetition conditions) was not supported. While the current study did not obtain a misinformation effect, the design used did provide support for previous SDT studies.
Single-massed-distributed (lag) repetition sequential lineups; Face recognition; Misinformation effect
The introduction of estimator (i.e., factors pertaining to the individual) and system (i.e., factors under the control of the justice system) variables to eyewitness testimony by Wells [1], has led forensic psychologists to study memory for faces and the influence of line-up structure for accurate face identification. The combination of these approaches has uncovered interesting information regarding witnesses’ ability to correctly identify the culprit in a line-up. Findings from studies that consider estimator variables such as eyewitness memory indicate that memory for events and people can be fallible and easily manipulated post-event [2-4]. In the following study we explore the interface between estimator and system variables, more specifically how system variables such as line-up structure, can influence the malleability of the memory trace. Robinson-Riegler et al. [5] claimed that, while eyewitnesses are able to identify a culprit from a series of photos, they are equally likely to misidentify individuals who resemble the culprit. For this reason Schuster [6] argued that the culprit in a police or photo line-up should remain indistinct from the others as this will reduce the risk of misidentification.
Luus and Wells [7] tested whether all individuals in a lineup should closely resemble the culprit. They found that a misidentification is less likely to occur in culprit-absent lineups when all individuals look very similar to the actual culprit. In culprit-present line-ups, however, accurate identification of the culprit is reduced when similarity across all individuals in the line-up is high. According to Clark and Tunnicliff [8], misidentification increases when individuals in the line-up have characteristics that closely resemble those of the culprit. Hence by chance alone, an innocent person can be selected in a line-up on the basis of resembling an image of the culprit on CCTV. Eyewitness errors of identification have led to many innocent individuals being falsely accused of an offence and consequently convicted [9,10].
Fitzgerald et al. [11] considered the impact of non-culprit individuals (i.e., ‘fillers’) present in the line-up structure. Schuster [6] as well as the Technical Working Group for Eyewitness Evidence (2003), suggest that the culprit should not stand out from the rest of the individuals shown in the line-up. Fitzgerald, et al. [11] suggested that ‘fillers’ should be of an ‘average resemblance’ to the suspect. For hypothesis one, they stated that low similarity line-ups will increase the identification rate. Hypothesis two stated that moderate and high similarity line-ups will increase the misidentification rate. Both hypotheses were supported. In the case of their second hypothesis, moderate or high similarity ‘fillers’ influenced misidentifications without affecting culprit identification.
The use of live line-ups, where all suspects are viewed simultaneously, was the traditional structure of an identity parade adopted in the UK [12]. In the UK today, however, video presentations have largely replaced live line-ups [12,13]. According to Horry et al. [14], a live line-up should conform to the Police and Criminal Evidence Act (PACE) 1984 [15] stipulations under ‘code D’. Code D is revised annually and currently stipulates that live line-ups should include eight volunteers in addition to the culprit [16]. In the US, for every culprit in the line-up, there must be at least five innocent volunteers [17,18].
According to Lindsay and Wells [19], when an eyewitness views all individuals simultaneously they base their selection on the relative judgement decision process. Wells [20] suggested that witnesses viewing faces simultaneously will compare one face with another in the line-up to ascertain which best resembles their memory of the culprit–hence a ‘relative judgement’ decision. This process works well under culpritpresent line-ups but under culprit-absent conditions the closest ‘lookalike’ is more likely to be selected. Wells [21] found that witnesses selected the culprit in 54% of cases (translating to a 46% misidentification rate) in culprit-present line-ups. In culprit-absent line-ups misidentifications increased to 68%. To help reduce this relatively high percentage of misidentifications in culprit-absent line-ups, Wells advocated a sequential line-up structure where faces are presented one at a time.
In sequential line-ups, the eyewitness is shown, one individual at a time [19]. This line-up format reduces the chances of misidentifications occurring [22,23]. Witnesses are more likely to make an absolute judgment by matching one individual’s face at a time with the encoded memory of the culprit’s face. Meissner et al. [24] argued that one reason why there are fewer misidentifications when using the sequential format relates to witness conservativeness. That is, they are less likely to make a selection.
Steblay et al. [22] performed a meta-analysis of 25 studies. The findings indicate that the type of decision making evoked by sequential line-ups reduces the chances of both misidentifications in culprit-absent line-ups and identifications in culprit-present line-ups. In the 2011 meta-analysis by Steblay et al. [22], simultaneous line-ups yielded an identification rate of 52% compared to 44% found in the sequential format. Misidentifications, however, were higher in simultaneous than sequential formats (28% versus 15%). Hence, although the hit rate was higher in the simultaneous line-up, so was the misidentification rate. Wells, et al. [25] randomly allocated eyewitnesses of real crimes to view faces presented in either the simultaneous or sequential line-up format. Although they found no overall difference between the two line-up formats for culprits identified (25%), the sequential line-up had fewer misidentifications (11%) when compared with the simultaneous format (18%). In the simultaneous line-up condition witnesses had a higher misidentification rate than in the sequential format condition (41% versus 32%).
The sequential line-up has been recently adopted by British police in the form of VIPER (Video Identification Parade Electronic Recording). The VIPER line-up structure consists of eight faces optimally matching witness’ descriptions. A full-face head and shoulder pose is followed by a ¾ profile to the right then left returning to a full-face pose. The whole sequence takes 15 seconds. The uses of VIPER line-ups and static photographs presented on screen have been empirically tested by Darling et al. [26] for eyewitness identification accuracy: no difference between the two formats in terms of identification rate was found. The new line-up video identification system, VIPER, allows eyewitnesses to observe the line-up twice. Hence, faces are repeated after seeing all eight faces conforming to a ‘lag 7’ repetition sequence (seven faces interpolated between the first and second presentation). Eyewitnesses who asked to see the identification parade using VIPER more than twice, made fewer identifications and more misidentifications than those who saw the line-up once or twice only [27]. This suggests that repetition in a lag-like manner increases the identification of target lookalikes. The position in the sequential line-up of the culprit and target lookalike’s faces influences both the identification and misidentification rate. This is illustrated by consistent findings of more misidentifications occurring when the target lookalike is presented late in the sequence. This can be explained using Signal Detection Theory (SDT).
Clark and Davey [28] showed that the individual most resembling the culprit is more likely to be selected when presented later than earlier (position 4 versus position 2) in culprit-absent line-up sequences. They claimed that eyewitnesses hold out for a better alternative when this ‘lookalike’ is presented early in the sequence: which can often lead to rejection of the line-up. Clark and Davey [28] explained the rejection of the line-up as a consequence of only low similarity individuals remaining in the sequence. To account for this rejection, Ebbesen and Flowe [29] suggested that eyewitnesses raise their threshold for deciding whether or not a face had been seen previously. Hence, they raise their decision criteria. In cases, however, where the lookalike occurs later in the line-up, then eyewitnesses ‘lowered their decision criteria’ and made their selection. Flowe and Ebbesen [30] supported this contention by manipulating the similarity to the culprit of one or more individuals in the line-up and changing their order of appearance in the sequence. Their findings support those of Clark and Davey [28].
This change in response criterion was previously considered in Signal detection theory (SDT) by Green and Swets [31]. The SDT approach provides a method of ascertaining how individuals distinguish between faces they have previously seen from faces they have not yet experienced. This can be measured through the number of faces correctly identified and faces incorrectly recognised. The standard paradigm for laboratorybased investigations of SDT involves a learning phase followed by a test phase. The learning phase typically involves a number of presentations. In the case of eyewitness studies, however, the learning phase is limited to a single observation followed by a test (identification) phase. Meissner et al. [24] presented a variation to this standard paradigm through the novel lineup recognition paradigm. Here, participants were shown many target faces which they had to identify in target-absent and target-present line-ups. During the learning phase they manipulated encoding strength by showing half of the sample (48) including the target faces once each at three seconds. For the other half (48), the target faces were shown twice which meant participants saw these faces for six seconds. During the test phase participants were presented with either the simultaneous or sequential line-up format. In the condition where target faces were repeated, participants showed significantly higher discrimination accuracy. There was no effect of line-up presentation or an interaction between encoding strength and line-up presentation on discrimination accuracy. Sequential line-ups, however, produced more conservative response rates, in support of Ebbesen, and Flowe’s [29] response criterion shift. The repetition of faces strengthened the memory trace and improved discrimination accuracy.
Repetition priming during learning phases to improve recognition at test is a well-established method in the guise of the ‘spacing paradigm’ [32-35]. Repeating a face twice improves recognition. Moreover, presenting it twice in a distributed manner (i.e., lag presentations) produces further increases of recognition over consecutive repetitions (known as massed presentation or lag 0; [34,35]. This improvement in memory is known as the ‘spacing effect’. Meissner et al. [24] used repetition of multiple target faces as a means of examining SDT.
In the current study, the culprit’s face is viewed in total three times (i.e., initially on CCTV footage and twice in a sequential photo line-up). Additionally, a distractor (a ‘lookalike’) face is included as part of the photo line-up which also contains other dissimilar looking faces to the culprit’s. As suggested earlier, Clark and Davey [28] showed that the most similar face to the culprit’s is more likely to be selected when presented later rather than earlier in the line-up. We adopt the spacing effect design to simulate the video presentation format used by many British police forces. As mentioned earlier, such videos have sequences of faces presented twice. The spacing effect design, in particular distributed repetitions, reproduces this format. The inclusion of a single presentation can be used to compare repetition effectiveness for culprit identification. As we are also interested in the impact of culprit and lookalike order of appearance on identification and misidentification rates, this can be explored using the spacing effect design. Moreover, the spacing effect format can be used to explore what happens to the original memory of the culprit’s face when new distracting information (such as the lookalike face) is presented prior to the culprit. To understand how a distracting lookalike face can interfere with the original memory trace of the culprit, we need to consider the misinformation paradigm first introduced by Loftus et al. [36].
Loftus [37,38] initially proposed that misleading post-event information can distort original memories via a ‘destructive updating’ process. Although Loftus considered that disruptive updating permanently erases information from memory, she has subsequently modified this notion [39]. The findings, it is argued, can be accounted for by impaired access to the original memory of an event after misleading post-event exposure. The misinformation effect could therefore be due to a retrieval failure rather than a ‘destructive updating process’ [40,41]. Despite limited evidence of destructive updating, the original memory trace clearly becomes less accurate once exposed to misleading post-event information thereby causing a misinformation effect. Loftus, [42,43] therefore considered the misinformation effect as resulting from new information interfering with the original memory which is then retrieved as the real memory of the event. Empirical support for the misinformation effect is robust [44-49]. In Loftus, and Palmer’s [45] classic study, a misinformation effect was found when witnesses to a traffic accident or theft event were presented with misleading post-event questions after viewing video footage [50]. This misleading post-event information reduced the recall accuracy of the original event.
Sequential line-up presentations help reduce the rate of misidentifications. It is possible to simulate such presentations by adopting a repetition approach based on the spacing paradigm. In particular, the distributed repetition structure resembles the sequential line-up where eight faces are shown one at a time and the whole sequence then repeated. The spacing paradigm predicts that information will be encoded more effectively when repeated. Hence, Hypothesis 1 (H1) states that identification of the culprit in repetition sequential line-up presentations will be higher than in single sequential line-up presentations. The spacing paradigm also predicts that learning information is effective under distributed (lag 7) presentations. Hence, Hypothesis 2 (H2) states that identification of the culprit will be higher in distributed than massed repetition sequential line-up presentations.
Signal Detection Theory predicts that in line-ups where the ‘lookalike’ face is presented early in the sequence and before the culprit, misidentification of the lookalike will occur less often. This is because the witness ‘holds out’ for a stronger match to the initial memory trace. Hence, Hypothesis 3 (H3) states that misidentification of the lookalike in single and repetition sequential line-up presentations will be lower when the lookalike is presented before the culprit rather than appearing after the culprit.
Alternatively, a misinformation effect is possible. The misinformation effect occurs when misleading post-event information is presented after the event. Misleading post-event information in this study was manipulated by presenting a lookalike face whose features overlapped strongly with those of the culprit. This was presented after the CCTV footage of the culprit but before the culprit’s face in the sequential lineup. Hence, Hypothesis 4 (H4) states that identification of the culprit in single and repetition sequential line-up presentations will be higher when presented before the lookalike rather than after. This is likely because the lookalike should interfere with the original memory of the culprit in the CCTV footage.
The inclusion of ‘fillers’ is important in sequential line-ups, but if they are too dissimilar to the culprit, then the culprit is likely to be chosen and, if too similar, then the ‘filler’ is selected [11]. A ‘filler’ that is similar to the culprit is more likely to be selected in culprit-absent sequential line-ups [8]. Hence, Hypothesis 5 (H5) states that misidentification in single and repetition sequential line-ups will be higher in culprit-absent than culprit-present line-up presentations. This also helps to ascertain the effectiveness of the manipulation of the lookalike’s resemblance to the culprit within the context of ‘other’ filler faces shown. Furthermore, there should be more misidentifications than false identifications in culprit-absent conditions.
180 first year psychology undergraduates (144 female and 36 male) who were novice to face recognition experiments from a UK university were randomly allocated to one of nine conditions. These conditions were based on the following variables:
All participants were presented with the same shoplifting footage which comprised the learning phase of this study (See Materials). The test phase was a between-subject design where participants were presented with one of three types of test phase line-up sequence (single versus two repetition conditions (massed versus distributed)); one type of culprit-lookalike face order (culprit before the lookalike and culprit after the lookalike) and culprit-present versus culprit-absent line-ups. Small groups of students from different seminar classes were collectively allocated randomly to one of nine test conditions ( See Supplementary material section).
The proposal for this research was passed by the Psychology Research Ethics Committee of Bath Spa University where students were recruited from. All participants were made aware that taking part in this study was on a voluntary basis and that they had the right of withdrawal at any time. Participants were assured that individuals could not be identified from the data they provided.
Black and white CCTV styled footage lasting 27 seconds was projected on to a screen. As it has been standard practice for UK police to make use of black and white CCTV footage, it was decided to maintain consistency with this practice. The fictitious footage shows a young adult male entering a ‘local corner shop’. He takes items and hides them under his clothing and unwittingly looks directly at the camera for one second. During the learning phase all participants viewed the same footage. There was no delay between the learning and test phase. During the test phase participants were presented with black and white photographs of full-frontal male faces produced in vignette style; each screened for five seconds. In order to be consistent with the CCTV footage, the photographs were also presented monochromatically. Each face had a sequence number which progressed numerically and corresponded with numbers on the response sheet. The culprit and lookalike faces contained overlapping features such that they appeared similar when presented separately but different when presented together. Ordering of slides during the test phase conformed to single and two repetition sequences (massed and distributed; see supplementary material section).
Participants selected the slide number corresponding to the face shown on screen they considered to be the culprit. It did not matter whether participants put one or two ticks for the repeated culprit or lookalike faces (or any of the other faces), as the culprit and lookalike faces never appeared before the other was fully presented in the sequence–this was especially pertinent for the distributed repetition sequence (lag 7). Moreover, participants were not informed of culprit-absent conditions as this would defeat the object of inducing false identification by selecting the lookalike face (See Supplementary material section for instructions to participants).
Although participants were permitted to make a ‘nonresponse’ (i.e., to tick none of the numbers), all of them actually did identify at least one image that they considered being the culprit. Table 1 shows the frequency counts (culprit, lookalike or other face) across single and repetition conditions with culprit first (C-L) or lookalike first (L-C) ordered presentations. There appear to be differences for correct and incorrect responses both within single and repetition conditions and across the different orders. Frequency counts for all conditions were analysed using hierarchical log-linear analysis as the data were nominal (i.e., can be correct (identification) or incorrect (misidentification) or any one selection from the ‘other’ faces (false identification) (See Table 1).
| Condition | Order | Results | ||
| C=identification | L=misidentification | Other=false identification | ||
| Single | C-L | 9 | 4 | 7 |
| L-C | 12 | 4 | 4 | |
| C-Absent | 0 | 7 | 13 | |
| Total | 21 | 15 | 24 | |
| Massed Repetition | C-L | 10 | 8 | 2 |
| L-C | 17 | 1 | 2 | |
| C-Absent | 0 | 10 | 10 | |
| Total | 27 | 19 | 14 | |
| Distributed Repetition | C-L | 7 | 13 | 0 |
| L-C | 16 | 4 | 0 | |
| C-Absent | 0 | 11 | 9 | |
| Total | 23 | 28 | 9 | |
Table 1: Frequency counts of culprit, lookalike or other face across non-repetition and repetition conditions with culprit and lookalike presentation order.
The overall relationships between identification, misidentification and false identification with single/repetition conditions and order of culprit and lookalike presentations were tested using a hierarchical log-linear model as an extension of multivariate statistics. Log-linear analysis is used to crossclassify sets of categorical data that can then be analysed by producing multi-way cross-tabulations (i.e., frequency tables and Chi2 ). As log-linear models make no distinction between independent and dependent variables, they can only indicate associations across variables. There are different types of model selection in log-linear analysis: build models, backward elimination and forced entry. A backward elimination model was used. Backward elimination models operate by progressively discarding variables until the reduction in Chi2 (Χ2) is no longer significant at the 0.05 probability level adopted. If the removal of the variable from the calculation has no significant effect, then it remains out and the next variable is considered. Backward elimination from a saturated model (all effects and all possible interactions between all variables) showed no significant impairment of the model by removing third and higher order interactions. The Goodness-of-Fit Tests indicate the model fits the data well (likelihood ratio Χ2 =14.183, df=12, p<0.05; Χ2 =11.471, df=12, p<0.05). The model can therefore be restated as including the interactions of order* results and condition* results.
Order* results cross-tabulation: Significant differences between Results (identification, misidentification and false identification) in the single and repetition sequential line-up presentations as a function of C-L, L-C and C-absent orders were obtained (Χ2 =17.593 (df=4, N=60) p<0.001; Χ2 =32.418 (df=4, N=60) p<0.0001 and Χ2 =39.568 (df=4, N=60) p<0.0001 respectively). The effect of size as measured using Cramer’s V for the single condition is 0.383; massed repetition is 0.520 and distributed repetition is 0.574. These are large effect sizes considering that 0.25 for four degrees of freedom is a large effect size [51]. According to Coe [52] reporting the size of the effect is important as it provides a measure of “quantifying the size of the difference between two groups” (p.1). Moreover, it is not confounded by sample size unlike a significance value. The effect of size scores indicates that there is a robust difference in the selection of culprit, lookalike and ‘other’ faces in the line-up due to their sequence positions. In the single and massed repetition conditions (See Table 1) for the C-L order, identification is higher than either misidentification or false identification. In the case of the distributed repetition, misidentification is higher than identification or false identification. When the L-C order is considered, identification is higher than either misidentification or false identification by a large margin. In the C-absent order, misidentification and false identification occur equally for the repetition conditions but misidentifications occur more often in the single condition. Identification, misidentification and false identification scores are plotted against C-L, L-C and C-absent orders as a function of single sequential line-up presentations in figure 1; as a function of massed repetition sequential line-up presentations in figure 2 and as a function of distributed repetition sequential line-up presentations in figure 3 (See Figures 1-3).
Figure 1: Shows the culprit, lookalike and other scores plotted against C-L, L-C and C-absent sequence order for single sequential line-up presentations.
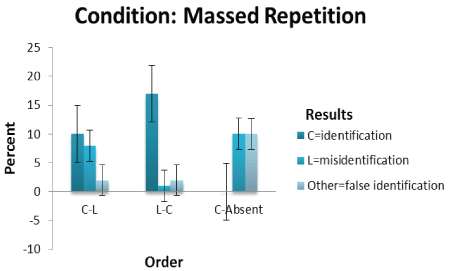
Figure 2: Shows the culprit, lookalike and other scores plotted against C-L, L-C and C-absent sequence order for massed repetition sequential line-up presentations.
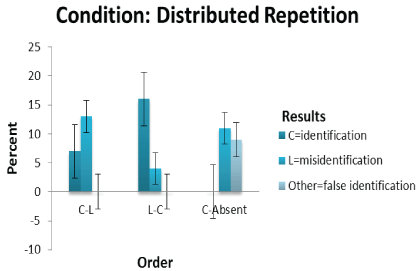
Figure 3: Shows the culprit, lookalike and other scores plotted against C-L, L-C and C-absent sequence order for distributed repetition sequential line-up presentations.
A. Breakdown by conditions: In the single sequential line-up presentation identifications is highest under the L-C compared to C-L order. This lends little support to H4 where identifications should be higher in C-L than L-C line-up presentations. Misidentification is the same for C-L and L-C orders (with the exception of distributed repetition where lookalike selection is higher) and occurs less often than false identifications in the C-absent line-up single condition. This provides support to H3 where misidentifications should be lower in L-C than C-L line-up presentations in line with predictions from SDT. The prediction of H5 that more misidentifications are made in C-absent than C-present line-up presentations is unsupported. By taking the figures from table 1, the z-ratio was used to calculate the difference between two independent portions (7/22=32% for single C-absent line-up presentation and 8/44 (4 from C-L and 4 from L-C; 18%) for single C-present lineup presentations)) a non-significant difference for a one-tailed hypothesis was found (p=0.1064).
In the massed repetition sequential line-up presentation the number of identifications is highest under the L-C compared to C-L order. This lends little support to H4 where identifications should be higher in C-L than L-C line-up presentations but supports H3 where misidentifications should be lower in L-C than C-L line-up presentations. Misidentifications are highest in the C-absent line-up. Misidentifications, however, are higher for the C-L order than the L-C order. There are more false identifications than misidentifications in the C-absent lineup presentation barring the massed repetition condition. H5 is partly supported in that more misidentifications than false identifications are made in C-absent than C-present line-up presentations for the massed repetition condition. By using the z-ratio to calculate the difference between two independent portions (10/22 (C-absent 45%) for massed repetition C-absent line-up presentation and 9/44 (C-present 20%) for massed repetition C-present line-up presentations; table 1) a significant difference for a one-tailed hypothesis was found (p=0.0172).
In the distributed repetition sequential line-up presentation the number of identifications is highest under the L-C than C-L order. Misidentifications are higher in the C-L than L-C order. There are more false identifications than misidentifications in the C-absent line-up presentation. This lends little support to H4 where identifications are predicted to be higher in C-L than L-C line-up presentations. H3 , however, is supported as misidentifications are predicted to be lower in L-C than C-L lineup presentations. Using the z-ratio to calculate the difference between two independent portions (11/22=50% for distributed repetition C-absent line-up presentation and 17/44=39% for distributed repetition C-present line-up presentations; table 1) a non-significant difference for a one-tailed hypothesis was found (p=0.1892). H5 is therefore not supported as misidentifications (in comparison to identifications) made in C-absent and C-present distributed repetition line-up presentations did not differ significantly. When the number of misidentifications and false identifications are compared in C-absent conditions, however, more lookalike than ‘other’ faces are selected in the massed repetition condition only. This partly supports H5 .
Condition* Results cross-tabulation: A significant difference between identification, misidentification and false identification in the C-L order was obtained across single and repetition sequential line-up conditions (Χ2 =14.085 (df=4, N=60) p<0.01)–hence, supporting a spacing effect. The effect size as measured using Cramer’s V for the C-L order is 0.343 (this is a large effect size at four degrees of freedom). In the case of L-C and C-absent orders non-significant differences across the conditions were obtained (Χ2 =6.933 (df=4, N=60) p>0.05 and Χ2 =1.741 (df=2, N=60) p>0.05) respectively. Nevertheless, Cramer’s V was 0.240 and 0.170 respectively. For the former, this is just below a large effect size of 0.25 and for the latter, just under a medium effect size of 0.21. Identification, misidentification and false identification scores were plotted against single and repetition sequential line-up conditions as a function of C-L order in figure 4; as a function of L-C order in figure 5 and as a function of C-absent order in figure 6 (See Figures 4-6).
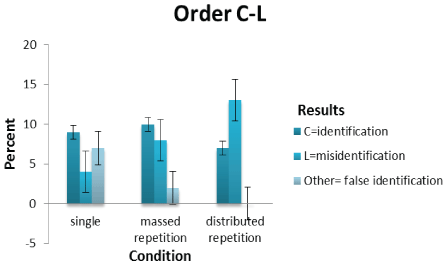
Figure 4: Shows the culprit, lookalike and other scores plotted against single and repetition conditions as a function of a C-L order.
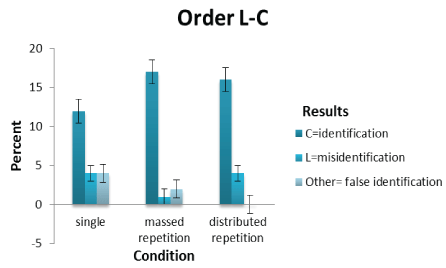
Figure 5: Shows the culprit, lookalike and other scores plotted against single and repetition conditions as a function of an L-C order.
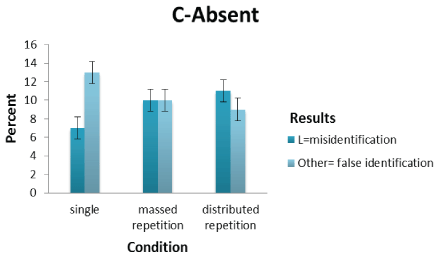
Figure 6: Shows the lookalike and other scores plotted against single and repetition conditions as a function of a culprit-absent order.
A. Breakdown by conditions: In the C-L order there is a significant effect of repetition on misidentification where there is a clear progression from the single-massed-distributed sequential line-up presentations (See Table 1). The large effect size supports this finding. Identification, however, shows a marginal decline from the massed to distributed repetition conditions and is only slightly increased from the single to the massed repetition condition (hence, not supporting H1). H2 , predicting that identification will be higher in distributed than massed repetition sequential line-up presentations, is not supported. A spacing effect for identification rate is therefore unsupported. H4 , predicting that identification in single and repetition sequential line-up presentations will be higher when the culprit is presented before the lookalike rather than after, is not supported as the direction of identification rate is in the opposite direction. As the lookalike appears after the presentation of the culprit, a misinformation effect is unlikely despite increased misidentification from the single to massed and to distributed repetitions. This is largely responsible for the significant effect.
In the L-C order no significant effect of repetition was found, however, there were some signs of identification increasing from the single to massed repetition line-up presentation but decreasing slightly in the distributed repetition (note that there is a strong effect size despite failure to reach significance). Misidentification decreased under massed repetition only to rise again in the distributed repetition line-up equalling the single condition. The effect size, however, provides support for identification occurring more frequently across conditions when the lookalike is presented before the culprit. This goes against there being a misinformation effect but provides support to SDT (claiming that identification occurs more frequently when the culprit face is presented later in the line-up sequence). Furthermore, there is little support for H2 as identification rate failed to show an increase across the two repetition conditions as predicted. In the C-absent order, misidentification over false identification increases from the single to massed repetition line-up and marginally in the distributed repetition line-up condition. Hence, despite showing some pattern effect of repetition, these did not reach significance but the effect sizes indicated differences in the number of times a lookalike was selected over ‘other’ faces across conditions (hence, suggesting a spacing effect). Based on the effect size for C-absent orders across all conditions, there is some support for there being more misidentifications than false identifications. However, there is partial support for H5 predicting that misidentifications in single and repetition sequential line-ups will be higher in culprit-absent than culprit-present line-up presentations (See Table 1). The significant effect occurs in the massed repetition condition, where more misidentifications than false identifications are found in the C-absent line-up sequence.
Misidentifications, however, increased in the C-L order across the single-massed-distributed repetition line-up conditions. This suggests that more misidentifications occur when the lookalike face appears later in the sequence (See table 1; lookalike selection in L-C versus C-L). These findings fail to provide support for the misinformation effect.
H1 is not supported based on data for identifications across single line-up (excluding C-absent) and massed and distributed repetition line-up presentations combined (excluding C-absent). By using the z-ratio to calculate the difference between two independent portions (21/44=48% for single line-up presentations and 50/88=57% for repetition line-up presentations) a non-significant difference for a one-tailed hypothesis was found (p=0.1616).
We inferred from the results of the Log-linear analysis a number of interesting findings. There was little support, however, for three of the five hypotheses. There was partial support for one hypothesis and statistically significant support for another hypothesis.
It was suggested in H1 that identification of the culprit in repetition sequential line-up presentations will be higher than in single sequential line-up presentations. The results failed to support this, instead suggesting that there is no advantage over single or repeated face presentations in sequential lineups for identification rate. Misidentification rate, however, increased from the single to the massed to the distributed repetition conditions. This occurred when the culprit appeared before the lookalike more so than when the lookalike appeared before the culprit. In line-ups where the culprit was absent, misidentifications increased conforming to the spacing effect (i.e., increasing from single to massed repetition to distributed repetition) while false identifications decreased (also contributing to a spacing effect). While there was support for a spacing effect, identification rate did not increase across conditions–hence, providing no support for H1.
It was suggested in H2 that identification rate will be higher in distributed than massed repetition sequential lineups. Identification rate failed to increase across repetition conditions-hence, providing no support for H2 (See H1 for comments regarding misidentification rate).
It was suggested in H3 that misidentifications in single and repetition sequential line-ups will be lower in lookalike before culprit orders compared to culprit before lookalike orders. This was found to be the case as increased misidentification occurred in culprit before lookalike orders only. Hence, misidentifications were highest in culprit before lookalike orders both within and between conditions–providing supports for H3 .
It was suggested in H4 that identification rate in single and repetition sequential line-ups will be higher in culprit before lookalike orders compared to lookalike before culprit orders. In the case of single sequential line-ups significant differences due to order were found, however, these were not in the direction stipulated in H4. In single and repetition conditions, identification rate increased in lookalike before culprit orders only–providing no support for H4.
It was suggested in H5 that the misidentification rate in single and repetition sequential line-ups will be higher in C-absent than C-present line-ups. Under the single line-up presentation the difference in number of misidentifications for C-present and C-absent line-ups failed to reach significance. The same was true of the distributed repetition line-up presentations; however, for massed repetition line-ups there was a significant difference. More misidentifications were made than false identifications in C-absent line-up sequences. H5 was true of massed repetition line-up presentations only where there were more misidentifications than false identifications made. Hence, H5 is partly supported. Why there were more misidentifications in C-absent line-ups for massed repetition only is interesting and difficult to account for. It is possible, however, that this result occurred as a consequence of the lookalike face being shown in quick succession. If the participant is unsure about the lookalike face when first shown, it is possible that an immediate repetition reinforces its saliency and increases the likelihood of a misidentification. In C-absent distributed repetition sequences, the second presentation of the lookalike face occurs later after seeing seven faces interpolated between its first and second showing. The saliency of the lookalike might be lost once a new face is presented. This would also occur in C-absent single presentation sequences.
Although results failed to support hypotheses 1, 2 and 4 and provided partial support for hypothesis 5, the findings corroborate the current literature on sequential line-up research. This is further supported by a significant finding for hypothesis 3 (see later). Hypotheses 1 and 2 were derived from the ‘spacing effect’ literature. In the literature it is stipulated that the recognition of a face increases when it is presented more than once. Moreover, when repeated in a lag 7 sequence (distributed repetition), recognition of faces is superior to that of lag 0 (massed repetition; [35]). One explanation for failing to obtain a spacing effect for identification hits might be explained by the design of this study. Repetition of faces is normally presented during the learning phase of an experiment, unlike in the current study where this was in the test phase. The intention was to use the spacing effect as a tool for testing recognition in a format similar to that of a video sequential line-up (comparable to VIPER). For this purpose, as a tool, the format worked well. Moreover, in the sequential line-up literature there is no reason why massed and distributed repetition should enhance identification rate. Repetition serves, however, to allow eyewitnesses to have another opportunity to see all individuals in the line-up. Although massed repetition is not representative of video sequential line-ups, distributed repetition is. As a tool, distributed repetition can be used to devise sequential line-ups analogous to those developed by the police. It can also be used in a non-applied context as a means of ascertaining the number of interpolated faces required to achieve optimal identification rates. Findings from such research can then be used by police in an applied context.
There was support for hypothesis 3 derived from the SDT approach. As predicted, increased misidentifications occurred in culprit before lookalike orders. Increased identifications occurred in lookalike before culprit orders (in line with SDT predictions). This can have implications for when a culprit’s face should be presented in the line-up sequence. We might ask would a sequential line-up be more reliable if all participants had overlapping facial similarities to the culprit? Perhaps presenting a sequential line-up of volunteers, each with overlapping similarities to the culprit (and not to each other), would reduce the number of misidentifications. Such a form of presentation might reduce the number of times a person who typically resembles the culprit (in both C-present and C-absent line-ups) is wrongly identified.
Hypothesis 4 was derived from the misinformation effect introduced by Loftus et al. [36]. Our findings failed to support the predictions of the misinformation effect. It was assumed that, once participants witnessed a shoplifter in a video footage, more identifications would occur in culprit before lookalike orders. In Hypothesis 4 it was predicted that more misidentifications would occur in lookalike before culprit orders, due to interference caused by the lookalike face. Hence, lookalike before culprit orders would cause a misinformation effect. Findings in this study, however, suggest that it makes no difference to the identification rate whether or not misleading information, in the guise of the lookalike face, is presented prior to the culprit. In fact findings suggest an increased identification rate in lookalike before culprit orders. Why the lookalike face in lookalike before culprit orders failed to interfere with culprit selection might be explained by robust memory traces created by participants when the footage was shown. Loftus et al. [36] suggested that, if a weak memory trace of a face is encoded and other similar faces are then shown, any one of these faces could interfere with the original encoding. Loftus’ misinformation effect does not appear to be confirmed using the current lookalike manipulations.
It can be argued, however, that our design failed to replicate the classic misinformation paradigm used by Loftus and Palmer [45]. The lookalike in their study would have been inserted as part of the narrative of the original event. The lookalike would therefore have appeared during post-event debriefing which contains misinformation presented at that point. This would have led to the misleading information becoming incorporated into memory assuming no discrepancy was perceived at this point. In our design, it is during the recognition task that the misinformation first appears. Hence, in our design it could be suggested that the lookalike, rather than being part of a design to detect a misinformation effect, accidently bears a resemblance to the culprit more so than the other faces presented.
Although Hypothesis 5 was partially supported, the literature on sequential line-ups suggests that more misidentifications occur in C-absent than C-present line-ups. In the current study there was no significant difference in the number of misidentifications occurring in C-absent versus C-present lineups. Only the massed repetition condition, however, yielded a significant difference between misidentification and false identification rates across C-absent line-ups. In this condition, the misidentification rate was higher than the false identification rate. The ‘relative judgment process’ (Link [53]) suggests that, when we are pre-exposed to a stimulus, a mental standard is formed and this is used to compare with other stimuli via a subtractive process. In the case of eyewitnesses, they are likely to select the person from a line-up most resembling the culprit and make this decision relative to other members of the line-up. As stated earlier in C-present line-ups the culprit is most likely to be identified. The person most resembling the culprit, however, was identified in C-absent line-ups. Our findings suggest a higher rate of identification (conditions collapsed) as opposed to misidentification in C-present lineups. Misidentification and false identification rates in C-absent line-ups (conditions collapsed), however, failed to differ significantly barring the C-absent massed repetition condition. Overall it can be inferred from these findings that a lookalike face was selected just as often as one of the ‘other’ faces in C-absent single and distributed repetition line-ups. This is not the case for the C-absent massed condition. It might appear that the lookalike face was poorly manipulated for likeness to the culprit; however, a different conclusion can be made when the order (culprit before lookalike and lookalike before culprit) is considered. It becomes clear that the likeness manipulation holds well as the lookalike is selected more often than one of the ‘other’ faces in C-present line-ups.
It is important, therefore that line-ups are carefully structured such that eyewitness’ descriptions reflect their memories of the culprit’s appearance. This, in turn, will have an effect on the volunteers selected to be part of the sequential line-up. By ensuring that all individuals are similar to the culprit (and hence, similar to the descriptions provided by eyewitnesses), increased identifications can be made in C-present line-ups and decreased misidentifications in C-absent line-ups [17].
The design used for this study might have been improved by increasing the level of ecological validity. Arguably, one way of achieving this is to present all line-up sequences as video footage. This may have been more in line with the VIPER system adopted by British police. We might also have made use of colour images rather than monochrome. While the spacing effect was used as a tool for presenting culprit before lookalike and lookalike before culprit orders, it was only the distributed repetition (or lag 7) sequence that was required to simulate a VIPER format. In future studies distributed repetition could be used to establish the optimal number of line-up volunteers required to improve identification and decrease misidentification and false identification rates. Furthermore, culprit and lookalike orders can be manipulated to stage more alternative positions in the line-up sequence. In this study the position of the lookalike and culprit were restrained by lag 0 and lag 7 presentations. Moreover, the second presentation of either the culprit or lookalike occurred before the first presentation of the culprit or lookalike in the sequence respectively. It would be interesting to see what happens to identification and misidentification rates were these restraints to be lifted.
Although we failed to uncover a spacing effect for identification rate, it was concluded that this design format could be used in an applied setting. In particular, distributed repetition can be applied to simulate video sequential line-ups used by many British police. Using the spacing effect design also allowed us to investigate the impact of culprit and lookalike order effects on identification rate. The order of lookalike before culprit yielded more identifications than misidentifications. This supported previous research concerning SDT. This design, however, was inappropriate for the investigation of the misinformation effect. Distributed repetition can be used in future research to investigate line-up order effects of culprit and similar looking foils. Furthermore, the number of face interpolations between the first and second presentation of the culprit can be manipulated in order to obtain the optimal lag required for increased identification. Findings derived from such research could be used to inform police of the best sequential line-up structure. For example, it appears that a lag of seven is, in fact, optimal. Our findings add support to their being advantages of using a sequential line-up format. This is illustrated by Wells [54] who jests, “Can I see the rest before I decide whether this is the person I want to identify as the murderer?” (p.14).
Download Provisional PDF Here
Article Type: RESEARCH ARTICLE
Citation: Taylor S, Workman L, Hall R (2018) To be or Not to be-Culprit or Lookalike that is the Question: Effects of Order on Single, Repetition and Culprit-Absent Sequential Line-ups. J Forensic Res Anal 2(1): dx.doi. org/10.16966/2577-7262.107
Copyright: © 2018 Taylor S, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Publication history:
All Sci Forschen Journals are Open Access